Posted by R. John Howe on 11-07-2006 11:57 AM:
Patterns in Ratings and Responses
Dear folks -
One advantage of a salon like this is that it permits modest systematic comparison
of responses. Even some modest analysis. Sometimes the visible patterns are
interesting.
We have summarized a bit and will post the results set by set over the next
few days.
Here is the summary and a little analysis of the ratings of the three yastiks.
Comments, criticisms, even requests to desist, are invited.

You can see that the range of scores for the yastiks was pretty wide, but it
that seems mostly due to isolated low and high scores rather than to a general
spread of scores across the scale.
Most folks gave Yastiks A and B middling ratings. Only Yastik C's ratings were
markedly low.
The anonymous expert rated Yastik A noticeably higher than did most of us, was
in the lower middle of the ratings for Yastik B and was part of the modal group
of low scores for Yastik C.
In one instance a rater rejected the scale, something that happened again with
other pieces.
Regards,
R. John Howe
Posted by James Blanchard on 11-07-2006 01:08 PM:
Hi John,
This is an interesting analysis. I hope you have the time, energy and interest
to do this with some or all of the other sets.
I would say that if there is a limited range, and all are in the mid-range of
estimates, that might say more about people's reluctance to give "strong" ratings
(positive or negative), rather than a strong consensus. I would say that a set
of 3's and a set of 6's is pretty strong disagreement given the usual tendency
for people to score these scales towards the middle.
Another analysis might be to see whether there is agreement on the relative
ranking within a set by individuals. This "ranking" analysis is probably a better
way of looking at the concept of "Good", "Better" and "Best" because it takes
out the vagaries of how people use the numeric scale. If you keep putting up
these tables I'll see if I have some time to do that.
James.
Posted by R. John Howe on 11-07-2006 02:09 PM:
James -
I'll do a few at least, just to demonstrate what this sort of array can show.
(I don't want to bore folks.)
Please do whatever additional you are moved to do.
You are right that most survey research folks believe that unless raters are
definitely "moved" by something they will tend to rate in middling positions.
This is part of what the two tiered rating scheme I proposed was designed to
counteract. Once a rater chose a position in an initial three alternative scale
he/she was asked to refine that indication with a second three position rating.
Unfortunately, I misestimated how strongly some raters would resist using Sack's
technically defined "Good" which he makes clear is definitely not. I was also
surprised at the resistance to using any numerical scale at all and to the objections
to the length of the one provided. Live and learn.
I actually have a 25-page array, by name, rating and ascending scores, with
rationales somewhat reduced (but not nearly enough for presentation). If you
want that, write me at rjhowe@erols.com and I'll send it your way.
Regards,
R. John Howe
Posted by R. John Howe on 11-07-2006 04:54 PM:
Shahsavan Mafrash End Panel Ratings Array
Dear folks -
Richard Tomlinson put up one of the sets of textiles for comparison and rating
in this salon that drew a large number of raters. (I apologize for misspelling
Richard's last name in some of these data arrays. I was moving a bit too fast
and without an editor.)
Here is my data array on the ratings of the Shahsavan mafrash end panels.

Although there were fairly wide distributions of scores on A and B, there was
also a visible tendency to give these two pieces middling to higher numbers.
But agreement broke down about how C should be rated. One four-person group,
including Mr. Tomlinson, felt that this piece deserved very high scores. But
another group with equal numbers rated this piece down quite seriously at the
3-4 levels.
Others may see additional noteworthy patterns in this data array.
Regards,
R. John Howe
Posted by R. John Howe on 11-07-2006 06:14 PM:
Yuncu Kilim Ratings Array and Controversy
Dear folks -
OK, I'm up for one more of these data arrays.
Another set of textiles that drew both quite a few raters and even some mild
controversy were the Yuncu kilims.
Here is my data array on the ratings of these three pieces.
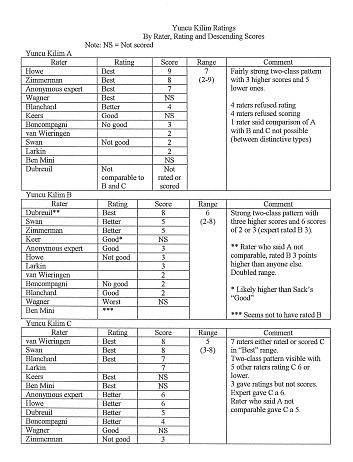
Piece B drew mostly low to middling ratings with only one high exception. My
anonymous expert gave it a 3.
Piece C drew a cluster of "Best" ratings and some associated higher number scores.
My anonymous expert gave it a higher middling score of 6. There were relatively
few lower scores.
The serious disagreements were about kilim A.
Only three people scored it high and most scored it quite low. But the real
problem was that the scorer who had objected to comparability of the jajim set,
made this argument again with regard to kilim A. He felt that comparisons could
not legitimately be made between kilim A on one hand and kilims B and C on the
other, saying they were two distinctive types.
Although my anonymous expert scored kilm A 7, he/she made a similar suggestion
about comparability saying that in fact each of these three pieces needed to
be rated as distinct types.
This led to a discussion of how to determine comparability. It does appear that
kilims B and C (of the polychrome group) have a coarser weave and heavier handle
than do pieces from the "red and blue " group from which A is drawn. This division
seems also evidenced by a distinctive end finish used only on red and blue group
pieces.
The rater, who objected to the original comparison, demonstrated, with examples,
how he would propose to group Yuncu kilims by design. This was a useful demonstration,
but the question was raised during it of whether design differences are a sufficient
basis for both detecting distinctive groups and for deciding what comparisons
are possible.
Others may detect further aspects of this data array and the associated vigorous
conversation, deserving of notice.
I plan to make some general comments about sets that did not draw many ratings
but this is the last data array of this sort that I plan.
Of course, the data I am drawing on is available to all of us in this conversation.
What I have done is transfer it to a Word table, printed the table document,
scanned it in jpg format, sent it as an email attachment to Steve Price, who
has put it up as a graphic that I use in my posts. So if you want to continue
you are now fully equipped to do so. 
My thanks to those who have offered their ratings and reasoning in this salon.
Regards,
R. John Howe
P.S.: Overnight Filiberto suggests that it is better to scan text in gif format
rather than the jpg one I advised above and used. He says compressed text in
gif format will produce less fuzzy characters.
Posted by R. John Howe on 11-08-2006 07:59 AM:
The Seeming Effect of Early Negative Comment
Dear folks -
There is one more general phenomenon visible in this salon that I want to point
out.
It is that if there is strong, early, negative or critical comment on a particular
set, not many subsequent ratings are attempted.
It happened to some extent in the case of the Quashqa'i "mille-fleurs," niche-design
pieces, after Marvin said he disliked them. We did get four raters, but, Wendel,
who was to be my anonymous expert, was sufficiently discouraged by the seeming
lack of interest in, and appreciation for, this format, that he did not rate
them himself, but simply provided a Moghul example that he felt indicated what
such pieces can be. (Note: My previous sentence has subsequently been made
untrue. Wendel has submitted his rating of the "mille-fleurs" examples I provided
and made further detailed analysis and comment on the aesthetic qualities of
this type. You can read what he has written in that thread.)
It happened in the case of the Shahsavan jajims from Moghan, after Louis questioned
their comparability (although he rated them himself from a strictly "occidental"
point of view, all, by the way, that the salon ever asked). Only he and I rated
this set.
And it happened with the last set of older Azarbaijan "silk embroideries," after
Sue seemed to say (her actual sentence does not parse) that she had never liked
suzanis and that these pieces made that dislike even stronger. I was the only
actual rater of these embroideries.
I'm not sure what happened with these sets. Maybe they are all simply of less
interest to those who participated in other sets. Perhaps they are instances
of varieties that are less familiar, and their relative strangeness made folk
reluctant to rate only on what they could see (notice that, if the latter is
the case, it indicates that we are often likely drawiing, as we rate, on on
information and aspects beyond the purely visual). But I wonder, too, if there
is not some hesitation to rate following a strong negative or critical comment.
Just musing.
Regards,
R. John Howe
Posted by Steve Price on 11-08-2006 08:21 AM:
Hi John
I can't speak for anyone but myself, but the reasons I made no comments about
any of those three sets were as follows:
1. Qashqa'i millefleur: I don't have enough of an aprpeciation of them to form
a set of criteria for judging them with which I'm comfortable. I've seen a few,
and thought they were stunning rugs, but never spent the time to develop a feeling
for what it was about them that struck me.
2. Jajim: The whole genre leaves me cold except for their tactile qualities,
which can be wonderful. That, of course, is outside the range of what we can
deal with in photos of rugs that are not in hand.
3. Azerbaijani embroideries: I know that these generate lots of collector interest,
but they do no more for me than most urban Persian carpets do. Like you, I was
baffled by Sue's linking them to Uzbek suzani, with which they share nothing
except the use of silk floss and the fact that they are embroidered.
Regards
Steve Price
Posted by Richard Larkin on 11-09-2006 10:57 PM:
John:
Some feedback grist for your mill. For my own part, negative response up front
instigates me forward if I am fairly strongly positive about the piece. Thus,
I was moved to jump in on the "mille fleurs" set when Marvin (that usual paragon
of good taste) gave them the back of his hand. Some I refrained from rating
because I didn't think I had much to say, the jajims, for example. I find them
reasonably pleasant, but not very moving, and I don't know much about the genre.
I would have passed on the Shahsavan panels, but I really liked C. (By the way,
you left me off that table. No offense taken, though.) I hate to encourage Sue,
but the Azerbaijani suzanis are not my cup of tea either.
I think the thread was (is) a big success, and much of the discussion was interesting
and illuminating; the Yuncu kilim set, for example, and many others too. I knew
I liked the mille fleurs "B" example, but I had a much better idea why after
reading Wendel's comments. As always, thanks for all the work in putting these
up.
__________________
Rich Larkin
Posted by Filiberto Boncompagni on 11-10-2006 02:50 AM:
quote:
Some I refrained from rating because I didn't think I had much to say, the jajims,
for example
I agree with Richard, it works the same for me...
I think it was an interesting exercise, anyway. You see how people use different
approaches in making their judgments. And someone used quite strong words too.
Regards,
Filiberto
Posted by R. John Howe on 11-10-2006 07:09 AM:
Rich -
I am sorry to have left your ratings out of the summary of the Shahsavan end
panels.
My only excuses are that I was working quickly, without either adequate clerical
skills or editorial assistance.
Regards,
R. John Howe
Posted by Richard Larkin on 11-10-2006 08:31 AM:
John,
Nothing to be sorry about here. The thing to be sorry about is that the "B"
mille fleurs entry isn't in my collection.
Cheers.
__________________
Rich Larkin
Posted by James Blanchard on 11-12-2006 10:03 AM:
Hi all,
Here are some further analyses from an epidemiologist stuck in a hotel room
in Pakistan on Sunday night....
There are two ways of looking at ratings. First, you can score ratings numerically
and then add up the average ratings to come up with an overall rating. Another
approach is to look at rankings, with the assumption that raters might be more
certain about rankings than numeric ratings.
So based on the rating data that John shared, here are a couple of analyses.
1. Overall rankings based on the relative ranking of raters.
2. Agreement on rankings from among all raters.
Yastiks....
A. Average ranking 1.6 (3 top rankings)
B. Average ranking 1.6 (4 top rankings)
C. Average ranking 2.6 (1 top ranking)
So, overall there was similar support for A and B as the best, and a fairly
strong consensus that C was the least good.
In terms of agreement on rankings, the overall percent agreement was about 48%.
In other words, overall the raters agreed on the relative rankings of the Yastiks
in just under 50% of the cases. Because there will be some agreement by chance,
I computed a statistic of agreement that looks at the level of agreement beyond
what would be expected by chance (Kappa statistic). Kappa was 0.22 for this
set, which is quite low.
Shahsavan Mafrash....
A. Average ranking 2.1 (3 tops)
B. Average ranking 2.1 (1 tops)
C. Average ranking 1.9 (5 tops)
Percent agreement: 48%
Kappa: 0.22
Note... the average rankings of these are close because there was a high degree
of polarity. Raters seemed to rank A and C at either end of the spectrum (first
or last), with B often in the middle, which brought up the agreement score.
Yuncu Kilim....
A. Average ranking 1.9 (4 tops)
B. Average ranking 2.4 (1 tops)
C. Average ranking 1.5 (6 tops)
Percent agreement: 29%
Kappa: -0.06 (actually LESS agreement than expected by chance).
My summary... it's a good thing weavers were able to bring diversity to their
basic design idioms because collectors have different taste.
Don't you think this sort of analysis would be interesting to do on a larger
sample? It might be interesting to include other assessments, such as dating
to see how much agreement there is on that.
Cheers,
James.
Posted by R. John Howe on 11-12-2006 04:49 PM:
Hi James -
Thanks for this further analysis.
Yes, the small N is always a problem in a group like this. Not sure what to
do about that.
But I was wondering underwhat circumstances statisticians would license doing
means on only part of a distribution?
I have been taught (and I'm no statistician) that with a small N the mean is
very sensitive to the extremes of the distribution and that the median is usually
seen to be more stable.
There, I'm already demonstrating one of the great problems with using statistics
at all. Very quickly the focus of the data is lost and one begins to talk mostly
about statistical methodology.
Regards,
R. John Howe
Posted by James Blanchard on 11-12-2006 09:45 PM:
Hi John,
You are right that such a small sample should be anathema to ANY statistical
analysis. Still, these simple analyses probably do capture the gist of the ratings.
I was calculating the average ranking, which has a range of only 1 to 3, so
there are no "outliers" to skew the distribution. It is not different from computing
what we call the "rank-sum", which is a non-parametric measure, meaning that
it doesn't depend on the shape of the underlying distribution (i.e. doesn't
assume a normal or bell-shaped distribution). Basically, a lower "rank-sum"
score means that in that group the set of raters gave that rug an overall higher
ranking, (irrespective of their numeric scores). A median is also a non-parametric
measure, but in this case it would probably not be very informative since the
range is so limited and it is quite possible for all of the rugs in each group
to have the same median rank.
Sorry for making a pretty simple dataset seem so complicated. 
James.
Posted by Steve Price on 11-13-2006 05:42 AM:
Hi John
You wrote, ... one of the great problems with using statistics at all. Very
quickly the focus of the data is lost and one begins to talk mostly about statistical
methodology.
You're right, of course. But the alternative is to not evaluate data at all
except when the conclusions from statistical analysis are so obvious in advance
that you can skip actually doing the analysis.
Regards
Steve Price
Posted by James Blanchard on 11-13-2006 09:04 AM:
Hi John and Steve,
In this case I think that the simple descriptive statistics do actually summarize
the rating process for these three groups of weavings more succinctly than could
be done by summarizing in words what we read in the posts and what is displayed
in John's tables. First, I think they accurately summarize the overall opinions
in terms of the relative rankings. Second, I think they clearly indicate the
lack of agreement in the rankings, and accurately indicate that opinions were
most varied for the Yuncu kilim.
Major Greenwood, an early pioneer of modern epidemiology summed it up in 1935
(1st half of the 20th century, for rug collectors) much more eloquently than
I could....
quote:
“The physician’s unit of study is a single human being, the epidemiologist’s
unit is not a single human being but an aggregate of human beings, and since
it is impossible to hold in the mind distinctly a mass of separate particulars
he forms a general picture, an average of what is happening, and works upon
that.”
James.
Posted by Sue Zimmerman on 11-13-2006 12:57 PM:
But James,
Answers can be succinctly crunched for understanding but never packaged so elegantly,
efficiently, purposely, and meaningfully, as are "germs" who's job it is to
recycle.
It has been known for years, statistically, for instance, that the most contaminated
objects in hospitals are physician's pens. What has come from that, I ask, but
stronger "germs"? Nothing. Sue
Posted by James Blanchard on 11-13-2006 02:12 PM:
Hi Sue,
I think that you underestimate the value of "answers crunched for understanding".
I won't bore everyone with the litany of discoveries made by an understanding
the distribution of diseases, and the public health good that has come from
this knowledge. Does this mean that all such knowledge is acted upon? Of course
not.
"Stronger germs", by which I suppose you mean those that are resistant to antibiotics,
are not developed ON doctors pens but rather through the ink emanating from
these pens. Antibiotic resistance is a result of inappropriate antibiotic use,
which is usually prescribed by doctors. Still, I agree that doctors should wash
their hands a lot.
But we are getting a long way from rugs now...
Cheers,
James.
Posted by Steve Price on 11-13-2006 02:21 PM:
Hi Sue
What basis do you have for believing that the existence of germs on physicians'
pens is a significant factor leading to the development of antibiotic resistance
in bacteria (I am assuming that this is what you mean by "stronger germs", since
I can't think of a sensible alternative interpretation)?
If your point is that statistics can be misused and misinterpreted, you're right.
This empahsizes the importance of understanding statistics and using it properly;
it isn't a reason to abandon statistical analysis.
Steve Price
Posted by Richard Larkin on 11-13-2006 04:25 PM:
disease is rampant
James:
Did Major Greenwood find the time to address "rug fever" in epidemiological
terms?
__________________
Rich Larkin
Posted by R. John Howe on 11-13-2006 05:12 PM:
Very good, Rich. Now we're back to rugs.
I do know that it can be contracted in antique shops and of course, flea markets,
but also in fairly high class places (you'd think they'd have better prophylactics)
like museums.
Unlike some other areas of interest (say dog breeding and exhibiting, which
has a pretty regular cycle of five years between the purchase of the first show-able
dog and the day on which the divorce papers are filed) there seems no cure for
rug collecting once contracted.
Those who begin to collect rugs and textiles are usually stoppable only by the
grave. Very hungry rug people sometimes wear T-shirts confessing to their plight.
The T-shirts do not say "Will work for food." but rather "Will work for rugs."
Regards.
R. John Howe
Posted by Marvin Amstey on 11-13-2006 05:20 PM:
Sue,
Docs don't use pens (anymore), not even ball point pens, which have never been
impicated in sreading "germs". Docs are now using computers, and James is correct,
doctors over use antibiotics and don't wash their hands enough. I speak as a
doc an an ID subspecialist, but what's this to do with rugs???
Posted by R. John Howe on 11-13-2006 06:25 PM:
Actually, Marvin, Rich had just taken us off this tangent.
You have taken us back.
Regards,
R. John Howe
Posted by Richard Larkin on 11-13-2006 09:23 PM:
John:
Actually, I'm a survivor. I just log in on Turkotek from time to time to prove
I don't really need it. I'm not buying. Thank goodness. I think the rugs I bought
25 years ago are marked up on the average about ten percant over my cost. (That's
the end of my financial reporting, Steve.) Seriously, though, some of my favorite
pieces remain some of the ones I spent the least for. It is a bit frightening
how much one would feel one had to have a certain rug. For me, it was
pile. Often Baluch. They didn't have to be great, just OK. Oh well.
__________________
Rich Larkin
Posted by R. John Howe on 11-14-2006 02:07 PM:
Rich -
You don't mean "survivor," you mean "recovered" rug addict a category I suggested
didn't exist among the living.
I think you're the first one I've met.
We need to cherish you as a rare breed.
Best,
R. John Howe
Posted by Patrick Weiler on 11-15-2006 12:28 AM:
Scientific Proof
Richard,
Did you join a 12-step program, or did you quit "Cold Turkish"? 
Did the Rugs Unonymous Group (RUG) program give you a T-shirt reading "JUST
SAY NO TO RUGS"?
Will the next ACOR or ICOC sell T-shirts with "Buy Rugs, Not Drugs"?
I wonder if Tipper Gore will weigh in on this topic.
And, Marvin, wall to wall rugs have been shown to increase infections, but bare
wood floors with throw rugs are better for your health.
Patrick Weiler
Posted by Steve Price on 11-15-2006 05:41 AM:
Hi Pat
Your post reminds me that the late Heinrich Kirchheim, arguably the most aggressive
collector of rugs ever, used to wear a T-shirt that said "Say no to rugs". I'm
pretty sure I remember seeing a photo in HALI of him wearing it.
Regards
Steve Price
Posted by Richard Larkin on 11-15-2006 02:30 PM:
Patrick:
That was a "12 gul" program, and yes, I did take it. Regarding the "Buy Rugs,
Not Drugs" situation, I have a (tragic or hilarious) story (take your pick)
in that area that, alas, cannot be aired on the pages of Turkotek. To paraphrase
Dr. Watson in "The Adventure of the Naval Treaty," some time will have to pass
before the story can be safely told. If I ever buy you a beer at some upcoming
conference, which I'm sure to boycott, I'll share the details.
__________________
Rich Larkin